简 述: 本篇重点讲述如下:
- 乱码知识所涉及的大量知识点
- MinGW/MSVC 对于
"中文123"的 ANSI 字符串的字符串的默认编码理解 - MSVC 中一些强制转换为 GBK/UTF-8 的大坑说明
- 使用代码片对上面理论的验证
- 完成心愿:以一种优雅的方式在 MSVC 上使用 UTF-8 和 Qt 跨平台不乱码;同样源码亦可使用 WinGW 编译不乱码

本文仅适合想要深究和学习乱码的原因、以及了解编码等知识的读者 ,最后理解透彻均后,欲自行解决做手中实际的乱码问题;若你仅想找到一两行代码,临时解决当前所囧境,本文可能不适合你。
[TOC]
本文初发于 “偕臧的小站“,同步转载于此。
编程环境
本文的所有代码测试环境,均为 💻: win10 21H1 📎 Visual Studio 2017 📎 Qt Creator 4.15.0
背景
编程早晚皆会遇乱码,经常一些遇到”拿来主义”,经过 C + V,不假思索看效果,或行或不行。忽觉,不应如此,细一缕分析之,看其缘由,解惑之,记载于此。
emmm,若是没遇到过乱码,建议可直接关闭本文;顺便我由衷想说一句:

基础共识
在讲解编程乱码之前,先假定读者和我已有基本的 “字符,字节,字符串和编码” 理解共识,若是理解不够详细,可自行前往字符,字节和编码达成共识。
但其中一部分依旧强调一遍:
- ANSI 编码 表示本地化的一种编码,不同国家、地区的其编码方式不同,且之间互相不兼容。也被称之为 多字节编码 :每个字符使用一个字节或多个字节(并非是固定的 2 字节)。
- 字符 是一个抽象的符号,人们达成的一约定共识。如看到 ‘$’, ‘¥’ 即知其含义。
- 字节 是计算机中的一段存储空间,是一个 8 位的二进制数。
- ANSI 字符串 是形如
"中文123"这种格式的多个字符,其共占 7 字节,共 5 个字符。
乱码种类
在这里,我将乱码可以分为两类,或许其“称呼”不够准确(不必纠结),但倘若读者由其文字自行理解这两种的差异,和我达成共识了, 即为目的达到了(是语言的局限性??)。
⓵式 文件读取形式的乱码: A 软件编写了一个 test.txt 文件,里面包含中英文和符号。然后在本机使用 B 软件直接打开,发现乱码了;亦或是将此文件,发送另外一个外国的网友,然后同样使用 A 软件打开,却发现也乱码了。(此处 “发现乱码了” 含义为人看不懂,出现方块符号、或者古生僻汉字、菱形?等)
⓶式 含编程形式的乱码: 在 IDE 中,输出一个 “ANSI 字符串” 或者将其保存到字符串对象 string 、QString 等中,再终端输出,发现也乱码了。
其中⓵式的非常容易解决,其仅和“源码字符集” 有关,最常见的解决方式为换一个编码格式解析即可(过于简单不再讨论)。而⓶式的则和“执行字符集” 相关,比较复杂、涉及的知识点也比较多,也是工程师常遇到却难以解决、也是余文的篇幅内容。其差异见图示:

分析两种乱码
对于⓶式的乱码,一共涉及到如下环节(按顺序),如果有一个环节出现了问题,则会造成最终的终端打印出现乱码。
以文本 “我是汉字奇” 为例:
- 确定本机的字符编码
- 在 .cpp 中, 写入
我是汉字奇的“ANSI字符串”时,按下保存时,选择的编码格式为? - 将此“ANSI字符串”当参数,传递给 QString 时候,其字符编码为?
- IDE 编译 .cpp 时候,其执行字符集为?将其拷贝到内存中时候为?
- 输出到终端的时候,终端的字符集为?
补充说明(巨坑):
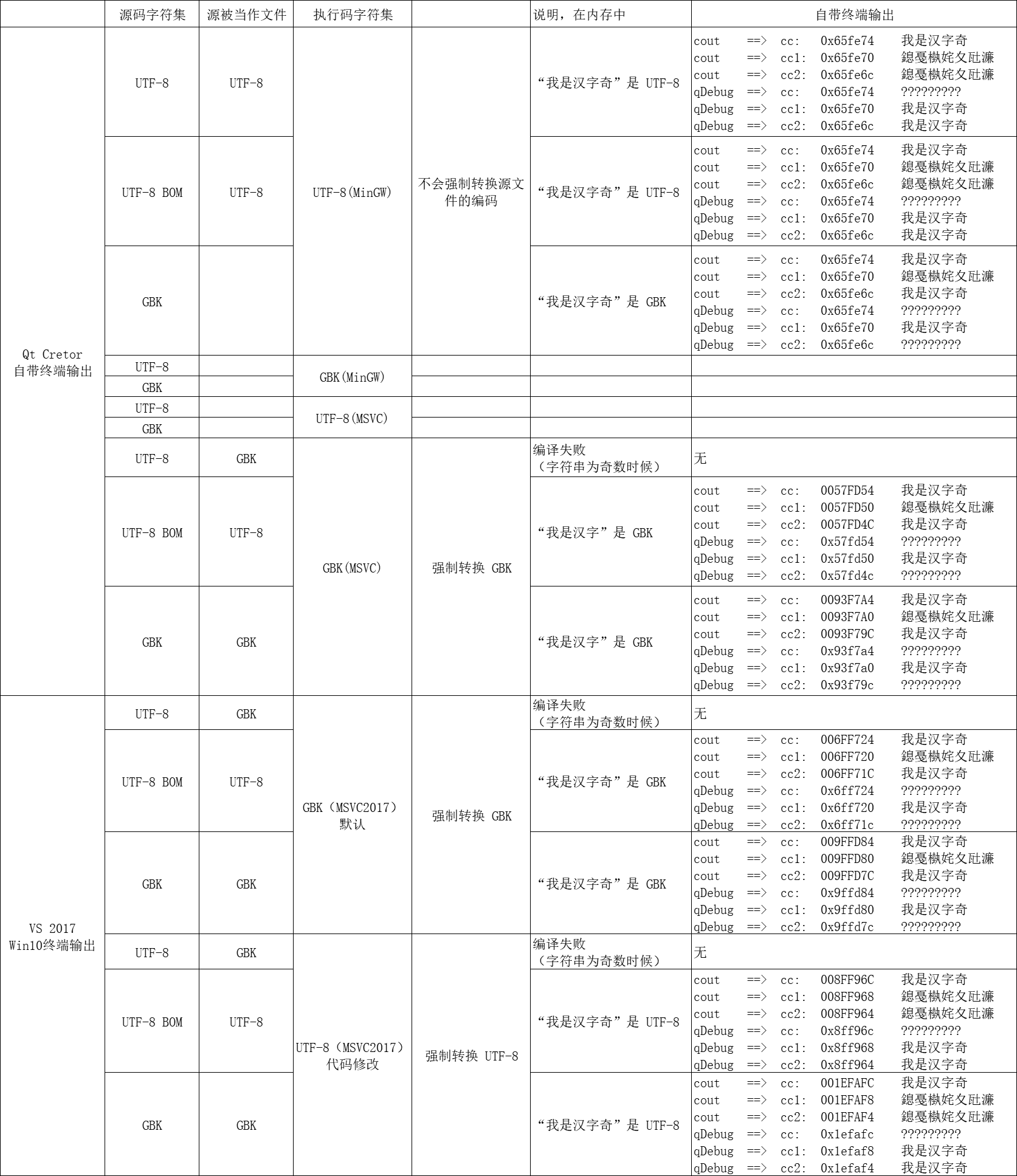
MSVC 的编码字符集和执行字符集都默认为 GBK;而 QtCretor 编码字符集和执行字符集都默认为 UTF-8。
MSVC 执行编译时候,发现近仅只能够将 “UFT-8 带 BOM” 格式的文件正确识别。而不带 BOM 的 UTF-8 实际也是被识别为 GBK 格式。
MSVC 在编译时,无论 .cpp 文件源码字符集是
UTF-8、UTF-8 BOM、GBK中的哪一种;只要没有声明为执行码字符集为 UFT-8,则最终在内存中,都会被强制转换 GBK 处理;若一旦声明,则也会被强制转换为 UTF-8 格式 。// 若想声明执行字符集为 UFT-8,添加如下 #pragma execution_character_set("utf-8")若测试的字符串
"xxxxxxx"为偶数,恰好会有“错错得对”巧合;故特地选择我是汉字奇这奇数个的中文来测试win10 终端默认的编码是 GBK,有时候还是很坑
字符串二进制的表示形式不需要编译,直接拷贝到执行程序的二进制中。
涉及的知识点
由上面的分析可以,牵涉的部分知识点大致包含如下;
- 源码字符集 和 执行字符集
- 字符编码 ANSI,GBK,UTF-8,UTF-16,Latin-1
- 统一码带 BOM 和不带区别?
- 代码页,本地编码,ANSI 编码
- MinGW/MSVC 中默认的编码
- MSVC 的特殊情况(见分析的补充说明)
- Qt/C++ 编码转换使用
- QString、QByteArrary、QChar、string、char *、char []、char
下面逐一解释其内容,内容较多、望君耐心。谁让历史的积累和包袱有这么多呢?已将关联不大部分,一笔带过。
.JPG)
源码字符集 和 执行字符集
| 名称 | 解释 |
|---|---|
| 源码字符集(the source character set) | 源码文件是使用何种编码保存的 |
| 执行字符集(the execution character set) | 可执行程序内保存的是何种编码(程序执行时内存中字符串编码) |
C++98 的问题: 既没有规定源码字符集,也没有规定执行字符集。 可参见【转】源码字符集(the source character set) 与 执行字符集(the execution character set)。
字符集/编码/ASCII/ANSI/UNICODE
按照惯例,人们认为字符集 和字符编码 是同义词,因为使用同样的标准来定义提供什么字符并且这些字符如何编码到一系列的代码单元(通常一个字符一个单元)。由于历史的原因,MIME和使用这种编码的系统使用术语字符集 来表示用于将一组字符编码成一系列八位字节数据的整个系统。
字符集(即 字符编码): 被收纳进入标准的 字符和符号的集合。
编码: 规定“字符集”中具体的某一字符存储的方式(字节数、哪些字节)。
但通常所说的 “字符集” 、 “编码” 与 “GB2312, GBK, JIS, Big5” 常有混用,应结合上下文理解到底说的哪一个含义。如 notepad++ 中集中常见的编码;
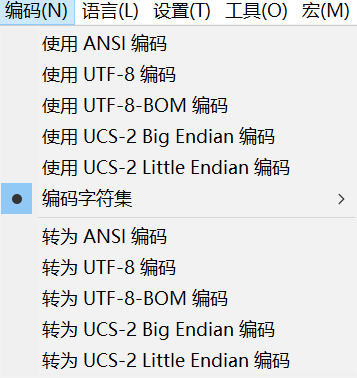
其分类为如下
| 分类 | 编码标准 |
|---|---|
| 单字节字符编码 | ISO-8859-1,ASCII |
| ANSI 编码(多字节) | GB2312(简体中文),BIG5(繁体中文),Shift_JIS(日本) |
| UNICODE 编码 | UTF-8,UTF-8-BOM,UTF-16(UCS-2 Big、UCS-2 Little) |
ASCII :只支持基本的拉丁字符的字符编码
ISO/IEC 8859 :在 ASCII 基础上加上一些扩展字符,是 15 种字符集。Latin-1 是其中之一。

不论是 ASCII 的 7 位的编码,还是后期演化出来的 ISO/IEC 8859 的 8 位的编码,都还是用单个字节就可以表示一个字符,叫做单字节编码。各种单字节编码之间的关系,可以用下面图表来解释:
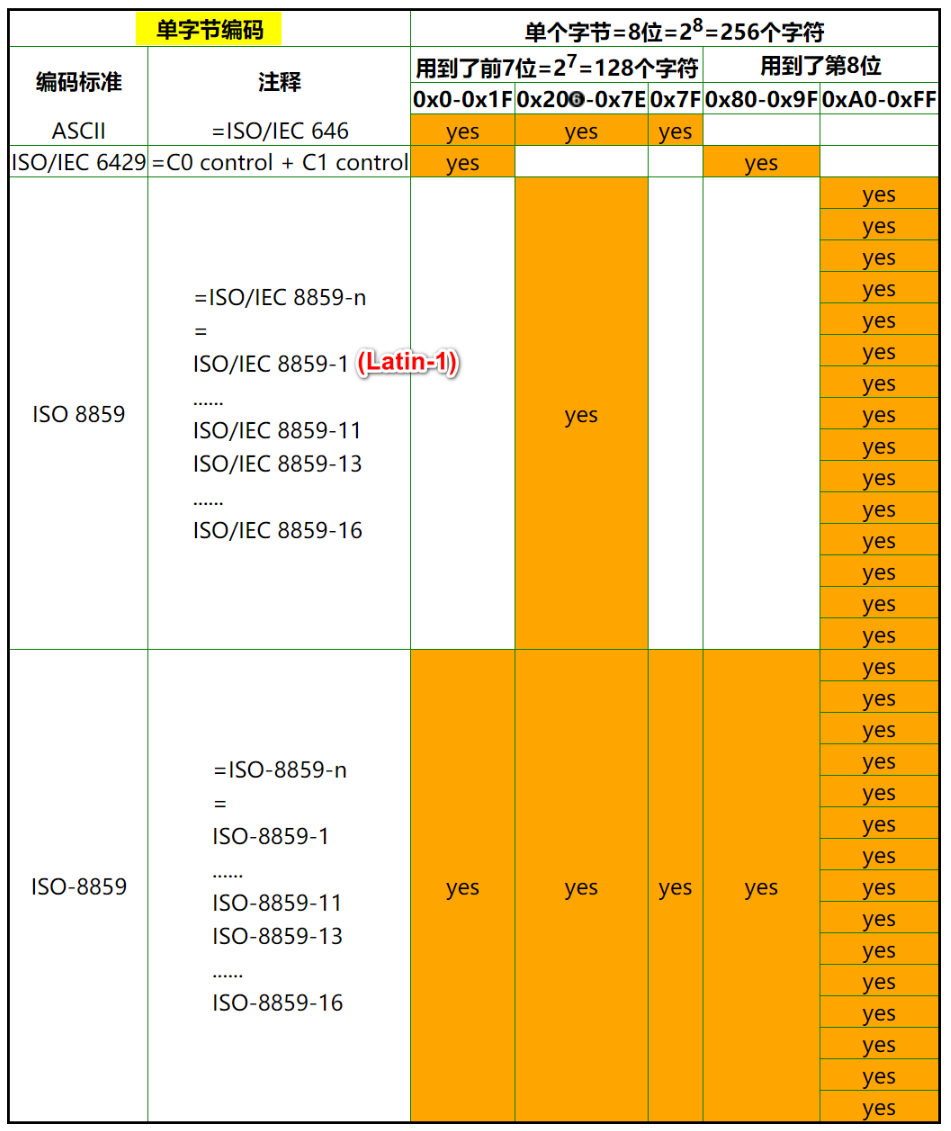
Unicode :只是一个符号集,它只规定了符号的二进制代码,却没有规定这个二进制代码应该如何存储。它的实现方式有如下:
- UTF-8 是一种变长的编码方式。它可以使用1~4个字节表示一个符号,根据不同的符号而变化字节长度。
- UTF-16 用二个字节存储一个字符。
- UTF32 用四个字节存储一个字符。
大端和小端(字节序)
大端(Big Endian) 认为第一个字节是最高位字节(按照从低地址到高地址的顺序存放数据的高位字节到低位字节);
小端(Little Endian) 则相反,它认为第一个字节是最低位字节(按照从低地址到高地址的顺序存放据的低位字节到高位字节)。
例子: 如 0x1234abcd 写入到以 0x0000 开始的内存中,则 Little endian 和 Big endian 模式的存放结果如下:
地址 0x0000 0x0001 0x0002 0x0003
big-endian 0x12 0x34 0xab 0xcd
little-endian 0xcd 0xab 0x34 0x12
UTF-8 带 BOM 与不带区别
BOM 就是一个标记,用于放在数据最开始的几个预定的特殊符号,并无特殊的含义。研究一通,最后发现就是本段第一行话。南墙在 UTF-8与UTF-8 BOM && 关于UTF-8的BOM:“EF BB BF”。
BOM Encoding
EF BB BF UTF-8
FE FF UTF-16 (big-endian)
FF FE UTF-16 (little-endian)
00 00 FE FF UTF-32 (big-endian)
FF FE 00 00 UTF-32 (little-endian)代码页,本地编码,ANSI编码
简单理解:仅在 Windows 系统中才有代码页面,在终端 chcp 可查看。一个代码页的数字,对应这一个字符编码。而 ANSI编码 就是使用的本机器默认的字符编码,本机的简体中文中为 GB2312 。
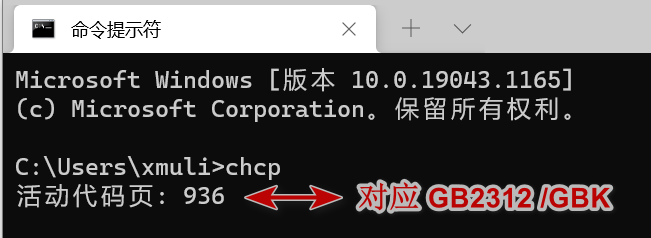
本地编码 :当前Windows中的二进制的值,用何种编码去解析,然后显示出对应的该编码中的字符。通常是指 ANSI 编码。
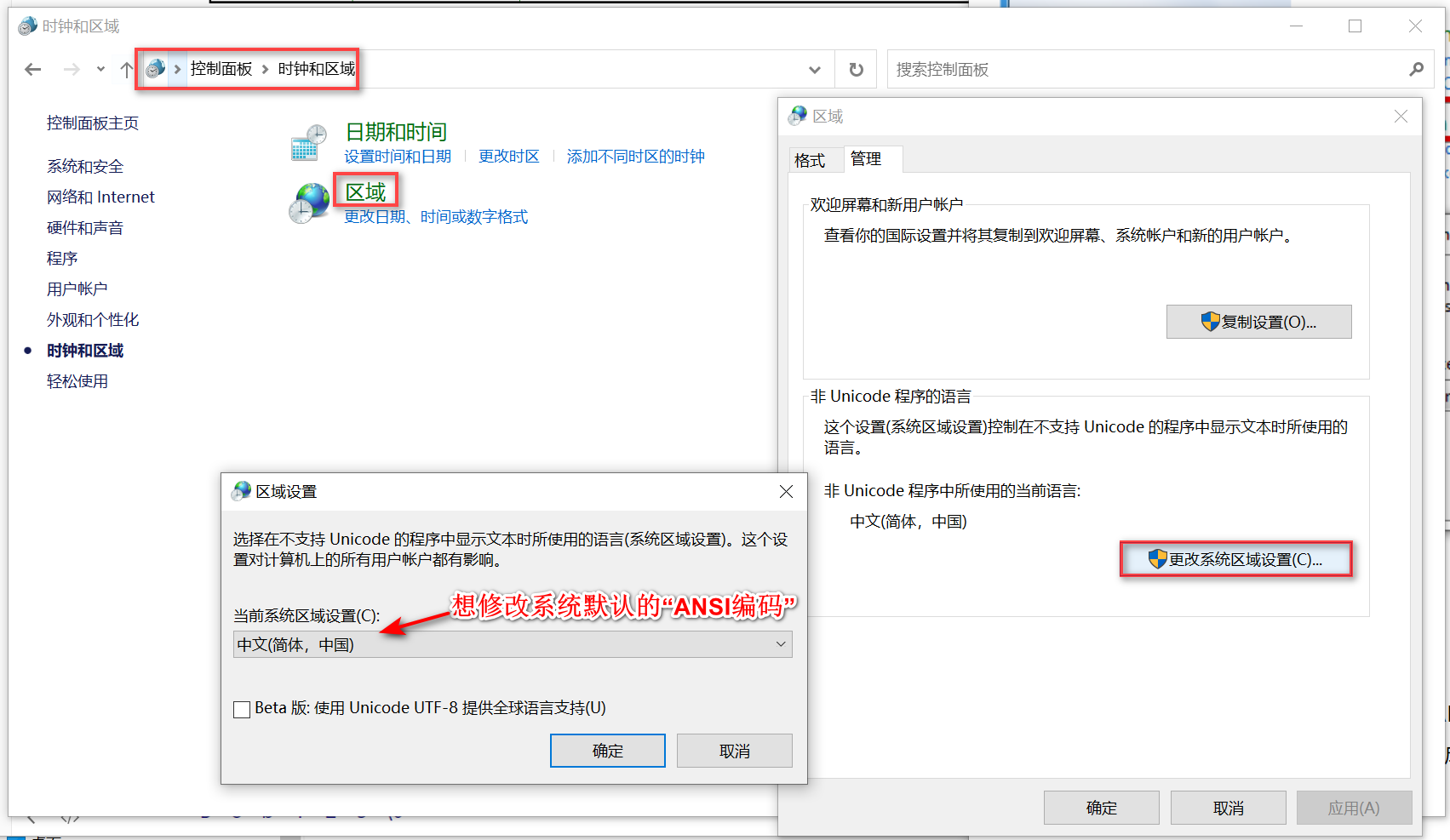
ANSI 编码 :使用2个字节(通常使用 0x80~0xFF 范围的2个字节来表示1个字符)来代表一个字符的各种汉字延伸编码方式。不同的国家和地区制定了不同的标准,由此产生了 GB2312, BIG5, JIS 等各自的编码标准。但是不同 ANSI 编码之间互不兼容,当信息在国际间交流时,无法将属于两种语言的文字,存储在同一段 ANSI 编码的文本中。
- 简体中文系统:ANSI 编码代表 GB2312 编码
- 繁体中文系统:ANSI 编码代表 BIG 编码
- 日文操作系统:ANSI 编码代表 JIS 编码
MinGW/MSVC 中默认的编码
这个里面属实有大坑,如下。
MSVC 的编码字符集和执行字符集都默认为 GBK;而 QtCretor 编码字符集和执行字符集都默认为 UTF-8。
MSVC 执行编译时候,发现近仅只能够将 “UFT-8 带 BOM” 格式的文件正确识别。而不带 BOM 的 UTF-8 实际也是被识别为 GBK 格式。
MSVC 在编译时,无论 .cpp 文件源码字符集是
UTF-8、UTF-8 BOM、GBK中的哪一种;只要没有声明为执行码字符集为 UFT-8,则最终在内存中,都会被强制转换 GBK 处理;若一旦声明,则也都会被强制转换为 UTF-8 格式 。// 若想声明执行字符集为 UFT-8,添加如下 #pragma execution_character_set("utf-8")若测试的字符串
"xxxxxxx"为偶数,恰好会有“错错得对”巧合;故特地选择我是汉字奇这奇数个的中文来测试win10 终端默认的编码是 GBK,有时候还是很坑
字符串二进制的表示形式不需要编译,直接拷贝到执行程序的二进制中。
C++/Qt 中字符串和编码
开发者自然重点关于 Qt 和 C++ 的字符串,以及涉及到的有关函数,以及里面内部的存储方式。
QString
QString stores a string of 16-bit QChars, where each QChar corresponds to one UTF-16 code unit. (Unicode characters with code values above 65535 are stored using surrogate pairs, i.e., two consecutive QChars.)
文档解释很清楚:QString 内部是以 16 位的 QChar 来存储(Unicode 的一种,但不是 utf-8)。
QByteArray
QByteArray can be used to store both raw bytes (including ‘\0’s) and traditional 8-bit ‘\0’-terminated strings. Using QByteArray is much more convenient than using
const char *.
QByteArray 既可以用来存储原始的字节,包括'\0',也可以用来存储传统的 8-bit 的以'\0'结尾的字符串。使用QByteArray比使用普通的const char* 更方便。
QChar
In Qt, Unicode characters are 16-bit entities without any markup or structure. This class represents such an entity. It is lightweight, so it can be used everywhere. Most compilers treat it like an
unsigned short.
在 Qt 中,Unicode 字符是没有任何标记或结构的 16 位实体。 这个类代表了这样一个实体。它是轻量级的,所以它可以被到处使用。大多数编译器把它当作一个 unsigned short。
| 转入函数 | 转出函数 | 描述 |
|---|---|---|
| fromLocal8Bit | toLocal8Bit | 与操作系统及本地化语言相关,Linux 一般是 UTF-8 字符串,Windows 一般是 ANSI 多字节编码字符串。 |
| fromUtf8 | toUtf8 | 与 UTF-8 编码的字符串相互转换。 |
| fromUtf16 | utf16 和 unicode | 与 UTF-16(UCS2)编码的字符串互相转换,utf16 函数与 unicode 函数功能一样, 注意没有 to 前缀,因为 QString 运行时的内码就是 UTF-16,字符的双字节采用主机字节序。 |
| fromUcs4 | toUcs4 | 与 UTF-32(UCS4)编码的字符串互相转换,一个字符用四个字节编码,占空间多,应用较少。 |
| fromStdString | toStdString | 与 std::string 对象互相转换,因为 C++11 规定标准字符串 std::string 使用 UTF-8 编码,这对函数功能与上面 **Utf8 转码函数相同。 |
| fromStdWString | toStdWString | 与 std::wstring 对象相互转换,在 Linux 系统里宽字符是四字节的 UTF-32,在 Windows 系统里宽字符是两字节的 UTF-16。因为不同平台有歧义,不建议使用。 |
| fromCFString fromNSString | toCFString toNSString | 仅存在于苹果 Mac OS X 和 iOS 系统。 |
QTextCodec:仅支持在非 Unicode 格式和 Unicode 之间进行转换。不能不同的非 Unicode 之间直接转换(如: Shift_JIS 和 GBK 之间不可直接转换、必须使用 Unicode 中转一次)
C++ 使用的字符串
在 C++ 中,以前通常使用 char 表示单字节的字符,使用 wchar_t 表示宽字符,对国际码提供一定程度的支持。 char * 字符串有专门的封装类 std::string 来处理,标准输入输出流是 std::cin 和 std::cout 。对于 wchar_t * 字符串,其封装类是 std::wstring,标准输入输出流是 wcin 和 wcout。
虽然规定了宽字符,但是没有明确一个宽字符是占用几个字节,Windows 系统里的宽字符是两个字节,就是 UTF-16;而 Unix/Linux 系统里为了更全面的国际码支持,其宽字符是四个字节,即 UTF-32 编码。这为程序的跨平台带来一定的混乱,除了 Windows 程序开发常用 wchar_t* 字符串表示 UTF-16 ,其他情况下 wchar_t* 都用得比较少。
MFC 一般用自家的 TCHAR 和 CString 类支持国际化,当没有定义 _UNICODE 宏时,TCHAR = char,当定义了 _UNICODE宏 时,TCHAR = wchar_t,CString 内部也是类似的。Qt 则用 QChar 和 QString 类(内部恒定为 UTF-16),一般的图形开发库都用自家的字符串类库。
在新标准 C++11 中,对国际码的支持做了明确的规定:
- char * 对应 UTF-8 编码字符串(代码表示如 u8”多种文字”),封装类为 std::string;
- 新增 char16_t * 对应 UTF-16 编码字符串(代码表示如 u”多种文字”),封装类为 std::u16string ;
- 新增 char32_t * 对应 UTF-32 编码字符串(代码表示如 U”多种文字”),封装类为 std::u32string 。
因为 Qt 有封装好的 QString,所以不太需要这些新增的字符串格式。
char *
- 如果是“窄字符/字符串”(以char为单位),那么不同的编译器可能不一样。以 VC++ 为例,它是由系统代码页决定的,比如在中文 windows 系统下就采用 GBK 编码。(算是 ⓶式的乱码的最开始原因)
- 如果字符/字符串前有指定编码方式,那没什么好说的了,就采用指定的编码方式,如下:
char* s1 = u8"hello"; //窄字符串,utf-8编码 (C++11)
wchar_t* s2 = L"hello"; //宽字符串,utf-16编码
char16_t* s3 = u"hello"; //宽字符串,utf-16编码 (C++11)
char32_t* s4 = U"hello"; //utf-32编码 (C++11)
//'\x12' : \x后面接2个16进制数字,可表示一个窄字符char,多个\x连起来可表示一个utf-8字符,如"\xE4\xBD\xA0"
//L'\u1234' : \u后面接4个16进制数字,可表示一个utf-16宽字符
//U'\U12345678' : \U后面接8个16进制数字,可表示一个Utf-32char []
通常情况下和可以 char [] 和 char * 进行混用,一个为形参,另一个为实参。
不同点为,详细可见 【C/C++】对char* 和 char[]区别的一些理解:
- char*是变量,值可以改变, char[]是常量,值不能改变。
- char[]对应的内存区域总是可写,char*指向的区域有时可写,有时只读
- char * 和char[]的初始化操作有着根本区别(指向常量区和赋值变量的栈区)
string
typedef basic_string
string; String class
Strings are objects that represent sequences of characters.
The standard
stringclass provides support for such objects with an interface similar to that of a standard container of bytes, but adding features specifically designed to operate with strings of single-byte characters.The
stringclass is an instantiation of the basic_string class template that useschar(i.e., bytes) as its character type, with its default char_traits and allocator types (see basic_string for more info on the template).Note that this class handles bytes independently of the encoding used: If used to handle sequences of multi-byte or variable-length characters (such as UTF-8), all members of this class (such as length or size), as well as its iterators, will still operate in terms of bytes (not actual encoded characters).
字符串类是 basic_string 类模板的实例,它使用 char(即字节)作为其字符类型,并具有默认的char_traits 和分配器类型(关于模板的更多信息请参见 basic_string )。
请注意,该类处理字节的方式与使用的编码无关。如果用于处理多字节或可变长度的字符序列(如 UTF-8),这个类的所有成员(如 length 或 size ),以及它的迭代器,仍将以字节为单位进行操作(而不是实际编码的字符)。
see: https://www.cplusplus.com/reference/string/string
char
char - 能在目标系统上最有效地处理的字符表示的类型(拥有与 signed char 或 unsigned char 之一相同的表示和对齐,但始终是独立的类型)。多字节字符串用此类型表示编码单元。对于每个范围 [0, 255] 中的 unsigned char 类型值,将该值转换成 char 再转换回 unsigned char 产生原值。 (C++11 起) char 的符号性取决于编译器和目标平台: ARM 和 PowerPC 的默认设置常为无符号,而 x86 与 x64 的默认设置常为有符号。
wchar_t - 宽字符表示的类型(见宽字符串)。要求大到足以表示任何受支持的字符编码位点(支持 Unicode 的系统上为 32 位。值得注意的例外是 Windows,其中 wchar_t 为 16 位并保有 UTF-16 编码单元)。它与上述整数类型之一具有相同的大小、符号性和对齐,但它是独立的类型。

see: https://en.cppreference.com/w/cpp/language/types
代码验证
光说不练可不行,故自行验证上面理论的代码片如下;
#include <iostream>
#include <QDebug>
using namespace std;
//#pragma execution_character_set("utf-8")
int main()
{
const char * cc = "\xce\xd2\xca\xc7\xba\xba\xd7\xd6\xc6\xe6"; // GBK
const char * cc1 = "\xe6\x88\x91\xe6\x98\xaf\xe6\xb1\x89\xe5\xad\x97\xe5\xa5\x87"; // UTF-8
const char * cc2 = "我是汉字奇"; // 是 10 或 15 字节,但一定是 5 个字符
cout << "cout ==> cc: " << &cc << " " << cc << endl;
cout << "cout ==> cc1: " << &cc1 << " " << cc1 << endl;
cout << "cout ==> cc2: " << &cc2 << " " << cc2 << endl;
qDebug() << "qDebug ==> cc: " << &cc << " " << cc;
qDebug() << "qDebug ==> cc1: " << &cc1 << " " << cc1;
qDebug() << "qDebug ==> cc2: " << &cc2 << " " << cc2;
return 0;
} 将上面代码分别在 VS2017 和 QtCreator 中验证;(取消)注释//#pragma execution_character_set("utf-8") 来验证;最后测试的验证结果如图 https://kdocs.cn/l/slqOBPQmfajc。
优雅在 Win 上使用 UTF-8 + Qt 跨平台
最初的愿望和其简单,只不过是想使用一套代码,既可以使用 MSVC + Qt + UTF-8 编译运行不乱码;也可以在 Linux + gcc + UTF-8 也不乱码。
综上的解决方案为同运行一下即可:
在 CMakeLists.txt 中添加如下代码
# 此处配合 VMSVC 的 UTF8-BOM 插件,达到跨平台 if ("${CMAKE_CXX_COMPILER_ID}" STREQUAL "Clang") message("---using Clang---") elseif ("${CMAKE_CXX_COMPILER_ID}" STREQUAL "GNU") message("---using GCC---") elseif ("${CMAKE_CXX_COMPILER_ID}" STREQUAL "Intel") message("---using Intel C++---") elseif ("${CMAKE_CXX_COMPILER_ID}" STREQUAL "MSVC") message("---sing Visual Studio C++---") add_compile_options("$<$<C_COMPILER_ID:MSVC>:/utf-8>") add_compile_options("$<$<CXX_COMPILER_ID:MSVC>:/utf-8>") endif()Visual Studio 中开发时候,所有 .h .cpp 文件都使用
UTF-8-BOM格式,可以安装ForceUTF8(withBOM)扩展
感觉这样子使用 utf-8 跨平台清爽了很多。 对于网上的添加 //#pragma execution_character_set("utf-8") 方式,则需要在每一个 .h/.cpp 中都加上这几行,相比之下只用在 cmake 中添加两行,则是优雅了很多。
#if _MSC_VER >= 1600
#pragma execution_character_set("utf-8")
#endif总结
关于使用 Visual Studio、Qt Crator 中容易出现的字符乱码问题;一般可重如下三个方面入手:⑴文件编码、⑵代码编码、⑶输出结果显示的编码。我们只要以此来检查这三部分,就可以找到乱码的原因,结合上面的每一个知识点的理解,即可更正。毕竟乱码的问题是由编码和解码方式不对引起的。
希望本篇能够协助读者彻底理解乱码原因后,最后均能可自行解决自己平台所对应的实际乱码问题,最终授人以渔。最后,若没啥疑问和问题的话?那我就要去准备喝汤了~~

回顾本文一些重点 key:
- 形如
"中文123"这种格式的 ANSI 字符串,其在不同编码下所占字节和字符个数? - 不同系统(默认的编码)对
"中文123"字符串是如何处理的? - MSVC 的一些大坑、以及强制转换 GBK/UTF-8
- 终端的编码是否会影响输出效果?


